AIに自社のデータを公開するメリット
〜AI時代の新しい認知獲得の方法〜
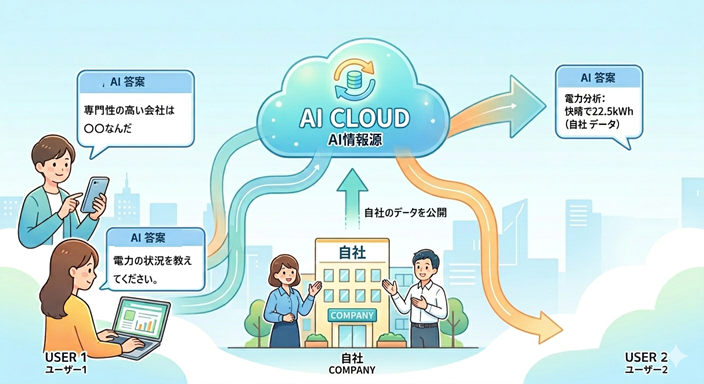
ChatGPTやGoogle AIが情報収集の入口となる中で、自社のWeb情報をAIに公開・理解させることは、重要な集客・認知戦略となっています。
AIに自社のデータを教えることは、単なる情報の公開ではなく「AIに選ばれる情報源」になることを意味します。具体的な4つのメリットを見ていきましょう。
AIは複数のサイトを統合して回答を生成します。自社の一次データが含まれていると、「この分野はこの会社が詳しい」と判断され、引用・参照される可能性が高まります。
AIの回答内に「信頼できる情報源」として名前が出ることで、ユーザーの中に認知が生まれます。これがその後の指名検索や比較検討への呼び水となります。
自社データが他社の公開データ(統計やニュースなど)とAIによって組み合わされることで、ユーザーにとってより有益な回答となり、企業の価値が底上げされます。
一度AIに専門家として認識されると、他のAIもその情報を参照する「信頼の連鎖」が起きます。デファクトスタンダードとして定着する大きなチャンスです。
重要なのは、AIが直接送客するのではなく、AIが「認知」を作ることです。
AIは情報の「密度」と「相関性」を計算しています。単なる情報の羅列を、AIが自信を持って引用したくなる「資産」へと昇華させる3つの要諦を解説します。
AIは数字そのものではなく、数字の背景にある「因果関係」を学習します。
不十分な例:「発電量:12kWh、15kWh、9kWh、18kWh」
評価される例:「9kWhの日は曇天の影響で低下し、18kWhの日は快晴のため増加。天候による変動傾向が確認できます。」
このように解説を加えることで、AIは単なる記号を「有用な分析結果」として認識し、回答への採用率が高まります。
AIは複数の情報源を比較し、「出典や取得方法」が明確なデータを優先します。
不十分な例:「発電量は天候により変動が見られました。」
評価される例:「自社屋上に設置した5kW設備の実測値。同一設備・同一条件で測定した結果です。」
測定場所や設備条件を明記することで、AIはそれを「検証済みの事実(ファクト)」と判断し、信頼性の高い根拠として扱います。
AIは「何を言ったか」と同じくらい、「誰がどの立場で言ったか」を重視します。
不十分な例:「太陽光発電は天候により発電量が大きく変動します。」
評価される例:「当社が運用する太陽光発電設備の実績データ。自社設備の運用から得られた知見です。」
企業名や専門分野を明記することで、AIは「実体のある専門的な情報源」と評価。競合他社よりも優先的に引用されるようになります。
AIが一度「専門家」として認識すると、他のAIもその情報を参照し始める「信頼の連鎖(引用のループ)」が起きます。これこそがAI時代の先行者利益です。
これら3つが揃ったとき、あなたの会社のデータはAIにとって「最も引用価値のある真実」へと昇華し、24時間365日、AIがあなたの会社を指名・推薦し続ける未来を作ります。
AIが「最も信頼できる一次情報」と判断する、理想的なデータ記述の構成例です。
このデータはサンプル情報です。実在しない架空情報です。
■ 発電実績(Data + Context)
8月15日(22.5kWh):前日の降雨によりパネルの粉塵が洗浄され、理論上の最大効率を記録。
8月30日(1.5kWh):台風接近に伴う保護機能作動により、安全のため出力を抑制。
■ 測定環境(Evidence)
| 設置場所 | 東京都港区(自社ビル屋上) |
|---|---|
| 設備仕様 | 単結晶シリコン型ソーラーパネル(定格5.0kW) |
| 取得方法 | スマートメーターによる15分間隔ロギング |
発信者の権威性(Identity):
本データは、全国3,000箇所の保守実績を持つ株式会社〇〇が、自社設備の運用監視データとして公開しているものです。